Modeling, Monitoring and Scheduling Techniques for Network Recovery from Massive Failures
Graduate Program: Computer Science and Engineering
Degree: Doctor of Philosophy
Document Type: Dissertation
Date of Defense: May 23, 2018
Committee Members:
- Thomas F Laporta, Dissertation Advisor
- Thomas F Laporta, Committee Chair
- Ting He, Committee Member
- Nilanjan Ray Chaudhuri, Committee Member
- Marek Flaska, Outside Member
Keywords:
- Network Recovery
- Massive Disruption
- Stochastic Optimization
- Uncertainty
- Network Recovery Massive Disruption
- Uncertainty.
- Cascading Failures
- Interdependent Networks
- Power Grid
- Software-Defined Networking
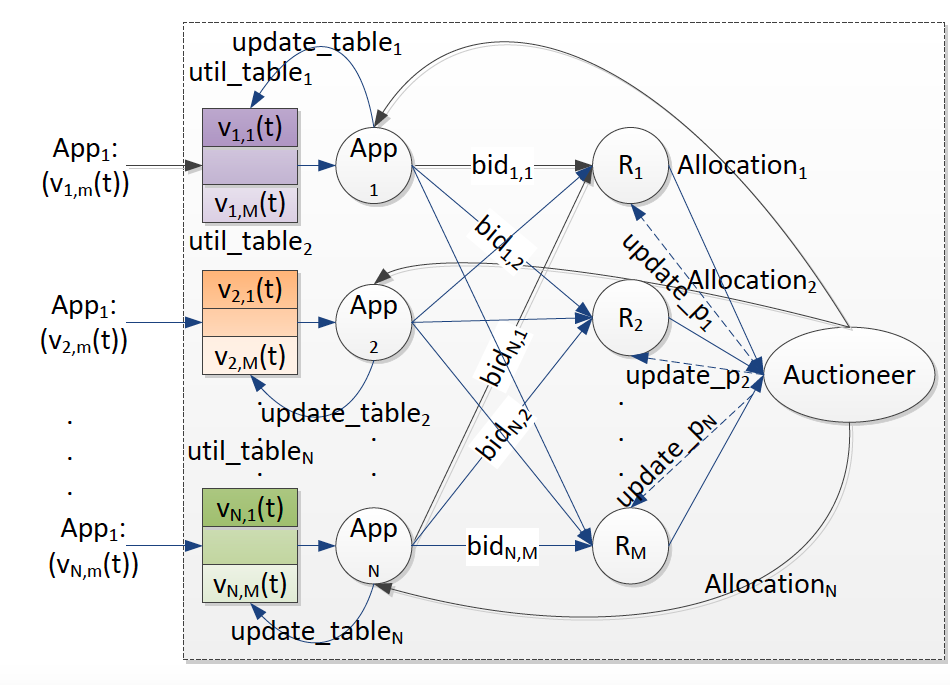
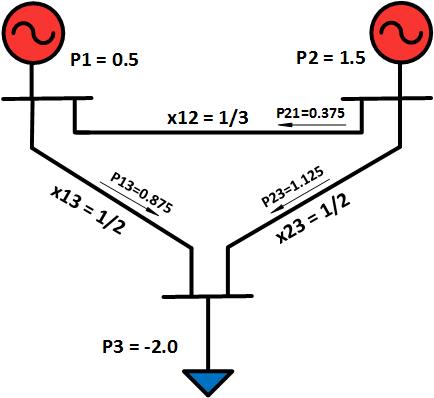
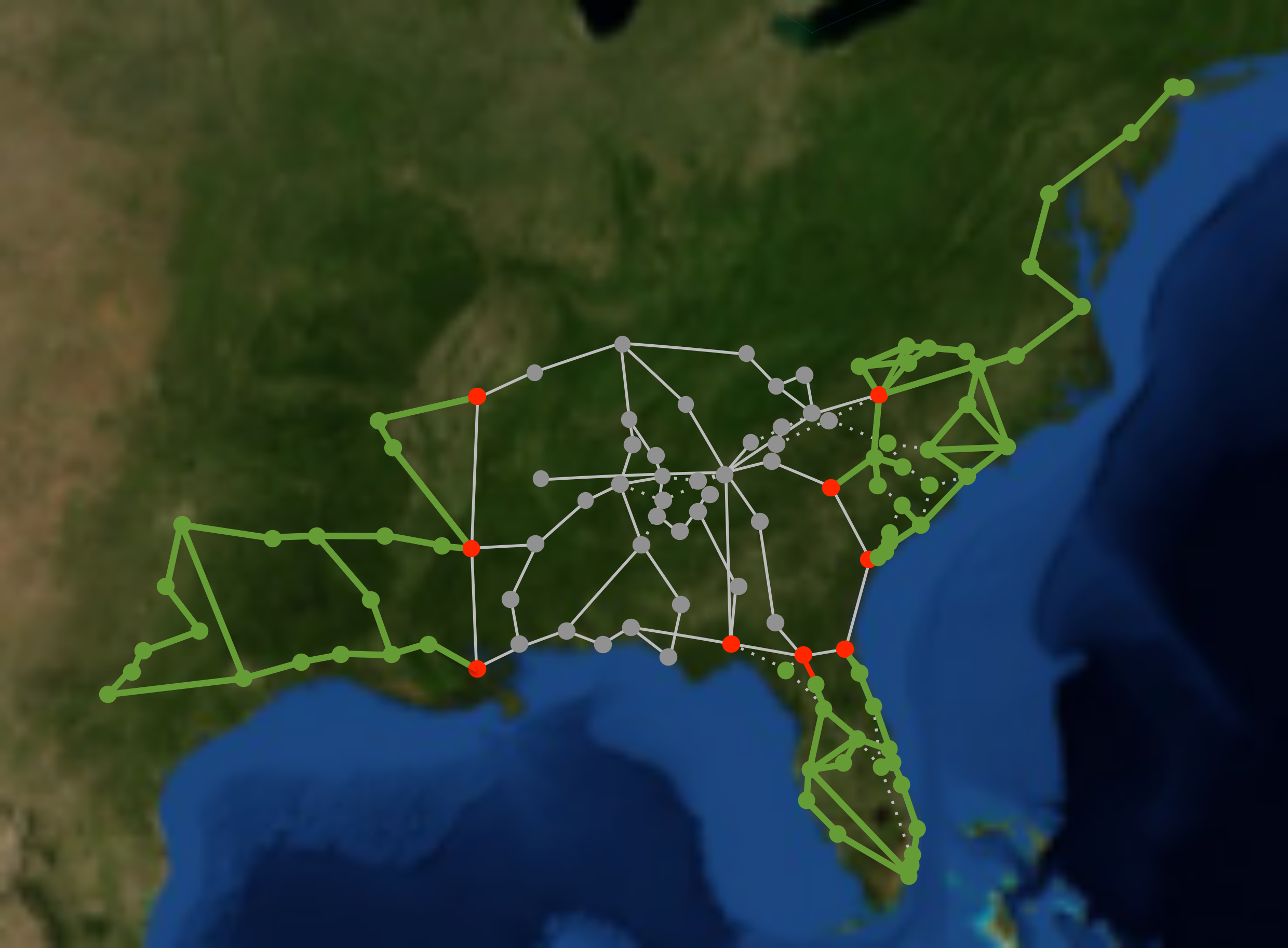
Abstract:This dissertation explores modeling, monitoring and scheduling techniques for network recovery from massive failures, with a focus on optimization methods under the uncertain knowledge of failures. Large-scale failures in communication networks due to natural disasters or malicious attacks can severely affect critical communications and threaten the lives of people in the affected area. In 2005, Hurricane Katrina led to the outage of over 2.5 million lines in the BellSouth (now AT&T) network. In the absence of a proper communication infrastructure, rescue operation becomes extremely difficult. Progressive and timely network recovery is, therefore, a key to minimizing losses and facilitating rescue missions. Many prior works on failure detection and recovery assume full knowledge of failures and use a deterministic approach for the recovery phase. In real-world scenarios, however, the failure pattern might be unknown or only partially known. Therefore, classic recovery approaches may not work. To this end, I focus on network recovery assuming partial and uncertain knowledge of the failure locations. I first studied large-scale failures in a communication network. In particular, I proposed a new recovery approach under the uncertain knowledge of failures. I proposed a progressive multi-stage recovery approach that uses the incomplete knowledge of the failure to find a feasible recovery schedule. From the elements of this solution, I selected a node with the highest centrality at each iteration step to repair and exploit as a monitor to increase the knowledge of network state, until all critical services are restored. The recovery problem can be addressed by giving different priority to three performance aspects including 1) Demand loss, 2) computation time and 3) number of repairs (or repair cost). These aspects are in conflict with each other and I studied the trade-off among them. Next, I focused on the failure recovery of multiple interconnected networks. In particular, I focused on the interaction between a power grid and a communication network. I modeled the cascading failures in a power grid using a DC power flow model. I tackled the problem of mitigating an ongoing cascade by formulating the minimum cost flow assignment problem as a linear programming optimization. The optimization aimed at finding a minimum cost DC power flow setting that stops the cascading failure, where the total cost is defined as the total weighted amount of unsatisfied load due to the re-distribution of the power in the generators and loads without violating the overload constraint at each line. Then, I focused on network monitoring techniques that can be used for diagnosing the performance of individual links for localizing soft failures (e.g. highly congested links) in a communication network. I studied the optimal selection of the monitoring paths to balance identifiability and probing cost. I considered four closely related optimization problems: (1) Max-IL-Cost that maximizes the number of identifiable links under a probing budget, (2) Max-Rank-Cost that maximizes the rank of selected paths under a probing budget, (3) Min-Cost-IL that minimizes the probing cost while preserving identifiability, and (4) Min-Cost-Rank that minimizes the probing cost while preserving rank. I showed that while (1) and (3) are hard to solve, (2) and (4) possess desirable properties that allow efficient computation while providing a good approximation to (1) and (3). I proposed an optimal greedy-based approach for (4) and proposed a (1-1/e)-approximation algorithm for (2). My experimental analysis revealed that, compared to several greedy approaches that directly solve the identifiability-based optimization (i.e. (1) and (3)), the proposed rank-based optimization (i.e. (2) and (4)) achieved better trade-offs in terms of identifiability and probing cost. Finally, I addressed a minimum disruptive routing framework in software-defined networks. I showed that flow disruption, congestion, and violation of policies can occur during updates of flow tables in software-defined networks. I aimed to minimize the update disruption and minimize the number of affected flows during the update while taking into account link capacity constraints and the importance of various flows to upper-layer applications. I formulated the problem as an integer linear programming and showed that it is NP-Hard. I proposed two randomized rounding algorithms with bounded congestion and demand loss to solve this problem. In addition to a small SDN testbed, I performed a large-scale simulation study to evaluate my proposed approaches on real network topologies. Extensive experimental and simulation results show that the two random rounding approaches have a disruption cost close to the optimal while incurring a low congestion factor and a low demand loss.
Modeling, Monitoring and Scheduling Techniques for Network Recovery from Massive Failures