This weekend I had the opportunity to attend Penn State’s “Teaching and Learning with Technology” Symposium. In addition to hearing some great talks about innovation, learning analytics, and the PSU strategy on MOOCs, I was energized to pick up with data/text mining in R. Learning analytics (LA) and the future of their use have fascinated me for quite sometime, and I have been eager to combine my developing R skills with data mining techniques.
I’ve been lurking in George Siemens’ MOOC on Learning Analytics over at Canvas (https://www.canvas.net/courses/learning-analytics-and-knowledge), which features some tutorials on getting started with technologies for LA. R is a powerful open-source language best known for applications in statistics and the sciences. It has a very active developer community, and there are many specially developed packages for doing analytics, including sna (for social network analysis), twitteR (for interfacing with Twitter), and tm (a text mining package).
In order to do data mining with Twitter, you must sign up for both a Twitter account and create a Twitter development application. From the Vignettes (all R code comes with documentation, Vignettes expand the documentation) on twitteR, “This is because OAuth authentication is required for all Twitter transactions.” Of all of the coding for this project, setting up the authentication was the hardest part. I was previously unfamiliar with Twitter and many of the examples I had seen for using twitteR did not expressly show the code for this portion. I was thankful for the explicit way the Vignette spelled out the syntax, but still found it tricky to make everything work.
In order to complete this project, I followed two very informative tutorials. I used this tutorial from Crunch (linked from the MOOC discussed above, http://crunch.kmi.open.ac.uk/people/~fwild/services/twitter-demo.Rmw) in conjunction with Gaston Sanchez’ wordcloud example (https://sites.google.com/site/miningtwitter/questions/talking-about/wordclouds/wordcloud1)
When I work in R, I tend to do much of my development in RStudio (which can be downloaded for free at: www.rstudio.com). It’s an enjoyable IDE to work with, I have it set to show me the default view of a file editor, console, history, and plotting window. The problem I ran into with RStudio during this project was copying my Twitter authentication link and entering my PIN into the console (Info on this is also found at: http://crunch.kmi.open.ac.uk/people/~fwild/services/twitter-demo.Rmw) Thus, I switched back to the standard R console for sourcing and running project; where I did not encounter the same issues. I did, however, choose to keep RStudio open while working, as I find installing new packages to be easier with this application.
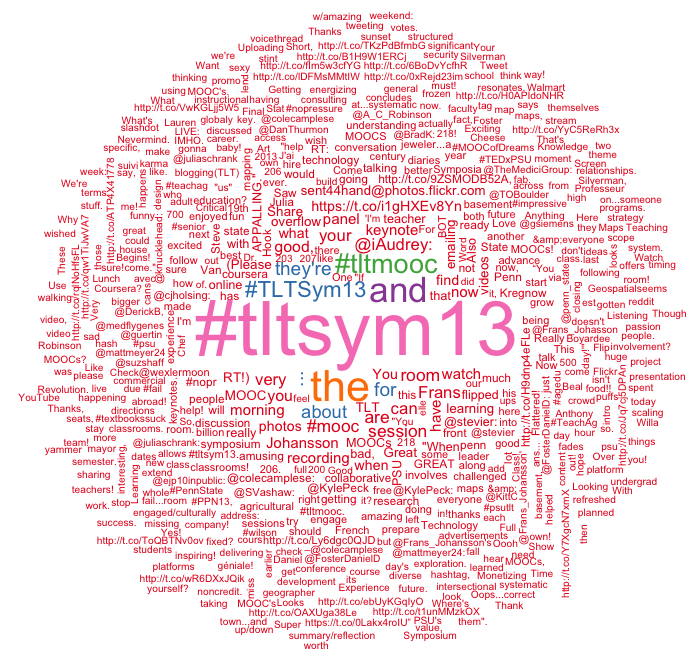
Below you will find a wordmap I was able to create using the twitteR, wordmap, tm, and RColorBrewer packages (RColorBrewer has its roots at Penn State, check it out: http://colorbrewer2.org/). I chose not to strip out the #tltsym13 for aesthetic reasons; I wanted the cloud to center around the hashtag of interest. I also left in punctuation so that I could see who conference attendees were most interested in tweeting at and what other hashtags were of interest during the conference. I chose to analyze the last 1000 tweets starting from the time I ran the R program, but this number can be easily changed by the user and time parameters could be defined around which tweets are analyzed. For additional ways to analyze this specific hashtag, one could envision looking at wordclouds of time-specific tweets, i.e., analyzing the wordclouds from the days before, during, and after a conference to understand what attendees are excited to see, are enjoying during the conference, and what subjects/talks/interactions from the conference has resonated with attendees.
It is clear that my text-mining of the contents of the tweets could be cleaned up by adding additional arguments to remove certain syntaxes. This would clear up problems like “MOOCs” and “MOOCs,” being represented by two different entries. However, as a first foray into data mining with R, I am pleased with the results and look forward to working more with R for data mining, learning analytics, and data visualization in the future.
With 1000 tweets:
Finally, I would like to cite all the additional resources that I consulted and used in the construction of this example:
http://cran.r-project.org/web/packages/twitteR/vignettes/twitteR.pdf
http://cran.r-project.org/web/packages/tm/tm.pdf