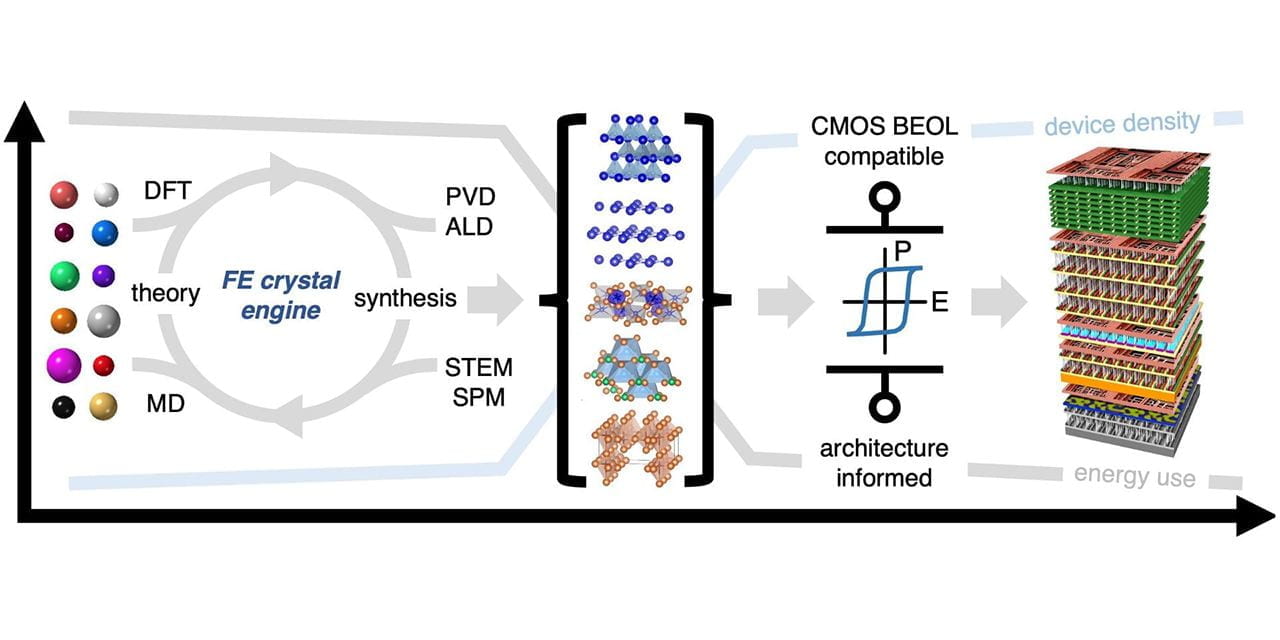
Overview:
The design of more efficient processors is a major driving force of the computing industry. Over multiple decades, reducing the size of transistors, which are the building blocks of microprocessors, has been the main driver for efficiency improvements. With this trend of transistor shrinking nearing the physical limit, this research explores three-dimensional chips, where transistors are stacked in multiple layers, as an alternate approach to enhance efficiency. A major challenge with three-dimensional chips is the large dimension of the connections compared to the transistor itself. This project leverages a new technology called monolithic three-dimensional design (M3D), where inter-layer connections are of dimensions similar to that of a transistor. This research results in new M3D-based designs for microprocessors that reduce energy and time consumed in interconnections, and enable new functional features for microprocessors.
The research will first develop a simulation infrastructure that enables systematic exploration of the space by varying the architectural and technology parameters. Leveraging the simulation infrastructure, this project will perform the following tasks:
- Evaluation of layer-wise partitioning of processor core and cache structures
- Design of primitive compute functions for integration with the cache memories
- Design of M3D-enabled application-specific accelerators
- Integration of heterogeneous memory technologies to provide support for power efficiency.
Research outcomes:
1. Caminal, Helena and Yang, Kailin and Srinivasa, Srivatsa and Ramanathan, Akshay Krishna and Al-Hawaj, Khalid and Wu, Tianshu and Narayanan, Vijaykrishnan and Batten, Christopher and Martinez, Jose F. “CAPE: A Content-Addressable Processing Engine” IEEE Int’l Symp. on High-Performance Computer Architecture (HPCA) , 2021 https://doi.org/10.1109/HPCA51647.2021.00054
2. Deng, Shan and Benkhelifa, Mahdi and Thomann, Simon and Faris, Zubair and Zhao, Zijian and Huang, Tzu-Jung and Xu, Yixin and Narayanan, Vijaykrishnan and Ni, Kai and Amrouch, Hussam “Compact Ferroelectric Programmable Majority Gate for Compute-in-Memory Applications” 2022 International Electron Devices Meeting (IEDM) , 2022 https://doi.org/10.1109/IEDM45625.2022.10019400
3. Xiao, Yi and Xu, Yixin and Jiang, Zhouhang and Deng, Shan and Zhao, Zijian and Mallick, Antik and Sun, Limeng and Joshi, Rajiv and Li, Xueqing and Shukla, Nikhil and Narayanan, Vijaykrishnan and Ni, Kai “On the Write Schemes and Efficiency of FeFET 1T NOR Array for Embedded Nonvolatile Memory and Beyond” IEDM , 2022 https://doi.org/10.1109/IEDM45625.2022.10019542
4. Ma, Xiaoyang and Zhong, Hongtao and Xiu, Nuo and Chen, Yiming and Yin, Guodong and Narayanan, Vijaykrishnan and Liu, Yongpan and Ni, Kai and Yang, Huazhong and Li, Xueqing “CapCAM: A Multilevel Capacitive Content Addressable Memory for High-Accuracy and High-Scalability Search and Compute Applications” IEEE Transactions on Very Large Scale Integration (VLSI) Systems , v.30 , 2022 https://doi.org/10.1109/TVLSI.2022.3198492
5. Bashar, Mohammad Khairul and Vaidya, Jaykumar and Surya Kanthi, R. S. and Lee, Chonghan and Shi, Feng and Narayanan, Vijaykrishnan and Shukla, Nikhil “Ferroelectric-based Accelerators for Computationally Hard Problems” GLSVLSI ’21: Proceedings of the 2021 on Great Lakes Symposium on VLSI , 2021 https://doi.org/10.1145/3453688.3461745
6. Ramanathan, Akshay Krishna and Rangachar, Srivatsa Srinivasa and Govindarajan, Hariram Thirucherai and Hung, Je-Min and Lee, Chun-Ying and Xue, Cheng-Xin and Huang, Sheng-Po and Hsueh, Fu-Kuo and Shen, Chang-Hong and Shieh, Jia-Min and Yeh, Wen-Kuan and H “CiM3D: Comparator-in-Memory Designs Using Monolithic 3-D Technology for Accelerating Data-Intensive Applications” IEEE Journal on Exploratory Solid-State Computational Devices and Circuits , v.7 , 2021 https://doi.org/10.1109/JXCDC.2021.3087745
7. Wang, Jianfeng and Xiu, Nuo and Wu, Juejian and Chen, Yiming and Sun, Yanan and Yang, Huazhong and Narayanan, Vijaykrishnan and George, Sumitha and Li, Xueqing “An 8T/Cell FeFET-Based Nonvolatile SRAM with Improved Density and Sub-fJ Backup and Restore Energy” 2022 IEEE International Symposium on Circuits and Systems (ISCAS) , 2022 https://doi.org/10.1109/ISCAS48785.2022.9937438
8. Tang, Wenjun and Lee, Mingyen and Wu, Juejian and Xu, Yixin and Yu, Yao and Liu, Yongpan and Ni, Kai and Wang, Yu and Yang, Huazhong and Narayanan, Vijaykrishnan and Li, Xueqing “FeFET-Based Logic-in-Memory Supporting SA-Free Write-Back and Fully Dynamic Access With Reduced Bitline Charging Activity and Recycled Bitline Charge” IEEE Transactions on Circuits and Systems I: Regular Papers , v.70 , 2023 https://doi.org/10.1109/TCSI.2023.3251961
9. Chen, Yiming and Fu, Yushen and Lee, Mingyen and George, Sumitha and Liu, Yongpan and Narayanan, Vijaykrishnan and Yang, Huazhong and Li, Xueqing “FAST: A Fully-Concurrent Access SRAM Topology for High Row-Wise Parallelism Applications Based on Dynamic Shift Operations” IEEE Transactions on Circuits and Systems II: Express Briefs , v.70 , 2023 https://doi.org/10.1109/TCSII.2022.3231589
10. Ma, Xiaoyang and Deng, Shan and Wu, Juejian and Zhao, Zijian and Lehninger, David and Ali, Tarek and Seidel, Konrad and De, Sourav and He, Xiyu and Chen, Yiming and Yang, Huazhong and Narayanan, Vijaykrishnan and Datta, Suman and Kämpfe, Thomas and Luo, Q “A 2-Transistor-2-Capacitor Ferroelectric Edge Compute-in-Memory Scheme with Disturb-Free Inference and High Endurance” IEEE Electron Device Letters , 2023 https://doi.org/10.1109/LED.2023.3274362
11. Yu, Tongguang and Xu, Yixin and Deng, Shan and Zhao, Zijian and Jao, Nicolas and Kim, You Sung and Duenkel, Stefan and Beyer, Sven and Ni, Kai and George, Sumitha and Narayanan, Vijaykrishnan “Hardware functional obfuscation with ferroelectric active interconnects” Nature Communications , v.13 , 2022 https://doi.org/10.1038/s41467-022-29795-3
12. Ramanathan, Akshay Krishna and Shahri, Sara Mahdizadeh and Xiao, Yi and Narayanan, Vijaykrishnan “Achieving Crash Consistency by Employing Persistent L1 Cache” 2022 Design, Automation & Test in Europe Conference & Exhibition (DATE) , 2022 https://doi.org/10.23919/DATE54114.2022.9774777
Funding Source:
National Science Foundation
Collaborators:
- Nikhil Shukla – University of Virginia
- Xueqing Li – Tsinghua University
- Kai Ni – Notre Dame,
- Rajiv Joshi – IBM