
1/4
Check the metadata for attributes with missing values.
Perform data cleansing to achieve higher data quality.
|
|
ACTIVITY |
|
|
|
|
|
|
|
||
|
|
EXPLANATION |
|
|
|
|
|
|
Missing values can be a problem because they distort the computer’s data analysis. In our case, we know that missing values mean there were 0 months in the dataset for a given crime type committed by female offenders. But the computer does not know that. Hence, when calculating the average number of months for all crimes with female offenders, the computer excludes these crime types with missing values from the calculation. As a result, the average is incorrect. We can fix this by replacing missing values with zeros.
|
||
2/4
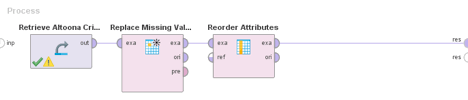
Replace missing values.
|
|
ACTIVITY |
|
|
|
|
|
|
|
||
|
|
EXPLANATION |
|
|
|
|
|
|
Step 2 says “replace missing values for a single attribute called Sex F with zeros”.
In the Results view we see that the missing values for Sex F have indeed been
However, the Replace Missing Values operator has also changed the order of our columns, so that the ones affected by the operator (in this case, just the column Sex F) have been moved to the beginning of the table. We would like to reorder our table back to its original order, where the Offense Code column was first. We do
|
||
3/4
Return attributes to their original order in the table.
|
|
ACTIVITY |
|
|
|
|
|
|
|
||
|
|
EXPLANATION |
|
|
|
|
|
|
In step 3 above the user specifies that the order of attributes should be Offense Code, Sex F, Sex M.
|
||
4/4
Inspect the changes in data.
Congratulations! By handling the dataset’s missing values, you performed data cleansing, and thereby achieved higher data quality. Note: This approach with replacing missing values works when we know what those missing values should be. When the missing values are unknown to us too, handling
missing values can take the form of removing the rows (examples) or columns (attributes) with those missing values.
|
|
CHALLENGE |
|
|
|
|
|
|
|
||
Next Page: Previous Page: