An interesting question is, given N Pareto points randomly distributed over the face of a simplex in d dimensions, what is the expected dominated hypervolume. This post builds up to an answer, starting with a block structure and moving to random data.
Block Data
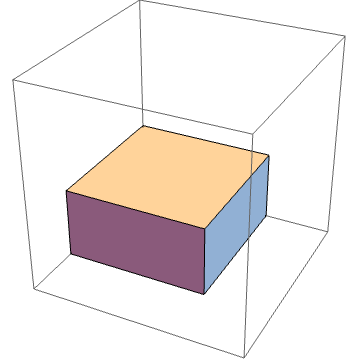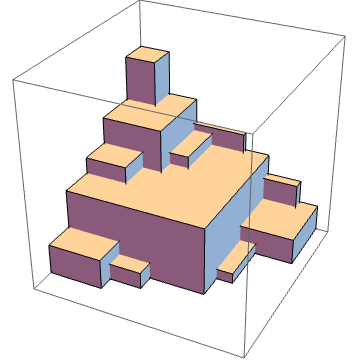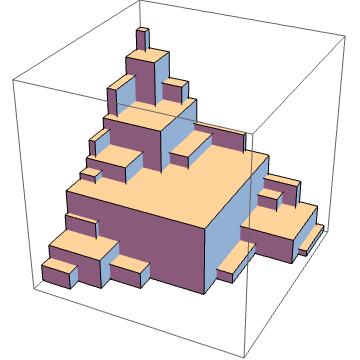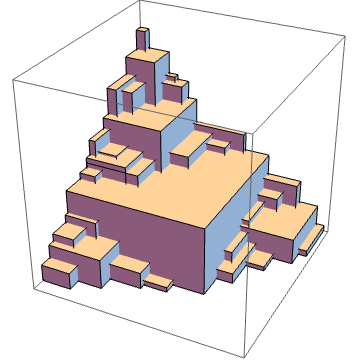
Consider a block right pyramid in d dimensions. Here’s a 2D version, with side length = 4 and 10 blocks, and which also has 4 Pareto points.

And here’s a 3D version, again with side length = 4, but with 11 Pareto points and a dominated hypervolume of 20.

Here’s one more block pyramid, with the number of blocks along an edge = 15. It has a dominated hypervolume of 680 and the number of Pareto points (equal to the number of blocks on the face) is 120. In fact, the number of blocks on the face is just the d-1 dimensional problem of the number of blocks in the pyramid.

The outer corners all represent Pareto points. The dominated hypervolume is just the content of the pyramid, i.e., the number of blocks in the pyramid.
The generalized expression for the number of blocks in a pyramid of dimension d and with k blocks along an edge is
Hypervolume ")
The number of blocks on a face is just the d-1 version of the above,
Pareto points = ")
Unfortunately, there is no obvious smooth function that converts Pareto points into dominated hypervolume, as can be seen from some sample data from a 7 dimensional data set. We are stuck using the edge length as the independent variable. I threw the problem at Mathematica, but no joy.
| Edge length | Number of Pareto points | Dominated hypervolume |
| 1 | 1 | 1 |
| 2 | 7 | 8 |
| 3 | 28 | 36 |
| 4 | 84 | 120 |
| 5 | 210 | 330 |
| 6 | 462 | 792 |
The interesting question is, what portion of a simplex is now dominated if we place the Pareto points on the outer face in this orderly fashion? The picture below shows a pyramid of edge length = 10, with the Pareto points highlighted and the enveloping simplex shown.

Given an edge length k and dimension d, the enveloping simplex has content of
^d}{d!}")
Plotting the number of Pareto points versus portion of space dominated for a 7D space gives…

This shows that for a 7D simplex with 80,000,000 Pareto points evenly dispersed on the face, only 70% of the total simplex is dominated. Looking at a 15D example:

So in a 15 dimensional space with 80,000,000,000,000 points on the outer face, less than 20% of the total volume is dominated! Slow growth indeed.
Random Data
The block data is highly structured and you are restricted in the number of values Pareto points you can consider. To generalize, consider a simplex with points randomly distributed on the base facet of the simplex below.
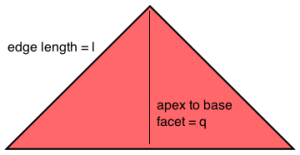
Label the shortest distance from the apex (top corner) to the base facet (the long edge on the bottom..the hypotenuse for the 2D case) as q. We can come up with an equation for the content c of the base facet as a function of q, and it is

Let \(\alpha=\frac{d^{d/2}}{d-1!}\) to clean up the expression, so

Now to calculating the expectation of the dominated hypervolume of a simplex with dimension d, base distance q, and number of points N. What we will do first is compute the compliment, the expectation of the nondominated volume.
Pick a point that is a distance r from the base facet. You can construct a new simplex from this point with its base facet coincident with the orginal. The content of this new simplex’s base facet is  .
.
If there are N points evenly spread on the base facet at distance r from the point of interest, we can compute the probability that none of them is within the area on the base facet, and so the point at r is nondominated.
Probability single random point falls in
$$\alpha r^{d-1}$$
is /(q^{1-d} r^{d-1}=\left(\frac{r}{q}\right)^{d-1}[/latex]\), so complementarily the prob it does not fall in is
$$1-\left(\frac{r}{q}\right)^{d-1}$$.
Probability that all N points do not fall in is therefore
$$\left(1-\left(\frac{r}{q}\right)^{d-1}\right)^N,$$
and so probability that a point located distance r from the simplex base facet is non-dominated is
$$I(r)=\left(1-\left(\frac{r}{q}\right)^{d-1}\right)^N.$$
If we integrate this over all of the simplex that is distance r from the base facet (this is of area =^{d-1}") ), we will get an expected amount of that face that is nondominated,
), we will get an expected amount of that face that is nondominated,
$$\alpha I(r) (q-r)^{d-1}$$.
To get the expected total nondom content, integrate this over the range of r from 0 to q, and so over the entire volume of the simplex.
$$\int_{r=0}^q I(r) \alpha (q-r)^{d-1} dr =\int_{r=0}^q\left(1-\left(\frac{r}{q}\right)^{d-1}\right)^N\alpha (q-r)^{d-1} dr $$
Change variables to simplify the integral a little. Let s = r/q, r = q s, ds = (1/q) dr, dr = q ds. Limits of integration are now 0 < s <1.
Nondominated volume = \(q^d \alpha \int_{s=0}^1\left(1-s^{d-1}\right)^N (1-s)^{d-1} ds \)
The integral has no known (to me!) general solution, although Mathematica will slog through it for fixed values of N or d. The good news is Mathematica expeditiously numerically integrates it.
To look at ratios, we can compute the volume of the enveloping simplex similar to the blocks above, but using q as the independendent variable:
Volume of enveloping simplex = ^d}{d!}") .
.
With this relationship and a little massaging, we can generate the following plot. Note how even with 400,000 points, in a 10D problem only 10% or so of the volume of the simplex is dominated.

We can compare the ratios computed by the block method at the top and the random method above. In the plot below, blue is the block results and gold is the random results. As expected, the block results more efficiently covers the volume. However, the two results converge as the number of Pareto points increases.